

- WEB DEVELOPMENT
- WEB DESIGN
- DIGITAL MARKETING
- IT CONSULTING
インターネットが産声をあげて以来、技術革新は止まることを知らず、無数の関連会社やサービスの乱立を経て、IT業界は今まさに、群雄割拠の戦国時代さながらの様相を呈しています。
しかし、その複雑さのあまり、ITを活用したいと考える事業者にとっては、正しい方向性を見出すのは、闇夜に針の穴を通すようなもの。
だからこそ、私たちは、この複雑なデジタルの世界を明るく照らし、誰もが迷わず目的地にたどり着けるように送り届けることにこそ、IT企業としての真の価値があると考えているのです。
いつの日か、巡り巡って、どうかあなたのお手伝いができますように。その日のために、是非、名前だけでも覚えて帰ってください。
株式会社WORLDEST(ワールデスト)といいます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import silhouette_score
class KMeans:
def __init__(self, n_clusters, max_iter=300):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = None
def initialize_centroids(self, X):
indices = np.random.choice(X.shape[0], self.n_clusters, replace=False)
self.centroids = X[indices]
def assign_clusters(self, X):
distances = np.array([np.linalg.norm(X - centroid, axis=1) for centroid in self.centroids])
return np.argmin(distances, axis=0)
def update_centroids(self, X, labels):
self.centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.n_clusters)])
def fit(self, X):
self.initialize_centroids(X)
for _ in range(self.max_iter):
labels = self.assign_clusters(X)
prev_centroids = self.centroids.copy()
self.update_centroids(X, labels)
if np.all(prev_centroids == self.centroids):
break
def predict(self, X):
return self.assign_clusters(X)
def inertia(self, X, labels):
total_inertia = 0
for i in range(self.n_clusters):
cluster_points = X[labels == i]
distances = np.linalg.norm(cluster_points - self.centroids[i], axis=1)
total_inertia += np.sum(distances ** 2)
return total_inertia
def silhouette_score(self, X, labels):
return silhouette_score(X, labels)
# Load and prepare the dataset
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and fit the KMeans model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X_train)
# Predict and evaluate the model
predictions = kmeans.predict(X_test)
accuracy = np.mean(predictions == y_test)
print("Accuracy:", accuracy)
# Calculate and display inertia
inertia = kmeans.inertia(X_test, predictions)
print("Inertia:", inertia)
# Calculate and display silhouette score
sil_score = kmeans.silhouette_score(X_test, predictions)
print("Silhouette Score:", sil_score)
# Visualize the clustering
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap='viridis')
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], s=300, c='red')
plt.title('KMeans Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import silhouette_score
class KMeans:
def __init__(self, n_clusters, max_iter=300):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = None
def initialize_centroids(self, X):
indices = np.random.choice(X.shape[0], self.n_clusters, replace=False)
self.centroids = X[indices]
def assign_clusters(self, X):
distances = np.array([np.linalg.norm(X - centroid, axis=1) for centroid in self.centroids])
return np.argmin(distances, axis=0)
def update_centroids(self, X, labels):
self.centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.n_clusters)])
def fit(self, X):
self.initialize_centroids(X)
for _ in range(self.max_iter):
labels = self.assign_clusters(X)
prev_centroids = self.centroids.copy()
self.update_centroids(X, labels)
if np.all(prev_centroids == self.centroids):
break
def predict(self, X):
return self.assign_clusters(X)
def inertia(self, X, labels):
total_inertia = 0
for i in range(self.n_clusters):
cluster_points = X[labels == i]
distances = np.linalg.norm(cluster_points - self.centroids[i], axis=1)
total_inertia += np.sum(distances ** 2)
return total_inertia
def silhouette_score(self, X, labels):
return silhouette_score(X, labels)
# Load and prepare the dataset
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and fit the KMeans model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X_train)
# Predict and evaluate the model
predictions = kmeans.predict(X_test)
accuracy = np.mean(predictions == y_test)
print("Accuracy:", accuracy)
# Calculate and display inertia
inertia = kmeans.inertia(X_test, predictions)
print("Inertia:", inertia)
# Calculate and display silhouette score
sil_score = kmeans.silhouette_score(X_test, predictions)
print("Silhouette Score:", sil_score)
# Visualize the clustering
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap='viridis')
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], s=300, c='red')
plt.title('KMeans Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
import random
import time
import threading
import queue
class AnimalChat:
def __init__(self, animal_names):
self.animal_names = animal_names
self.messages = queue.Queue()
self.responses = {
'Cat': ['Meow!', 'Purr...', 'Hiss!'],
'Dog': ['Woof!', 'Bark!', 'Grr...'],
'Cow': ['Moo!', 'Moooo...', 'Mooo!'],
'Duck': ['Quack!', 'Quaaack!', 'Quack quack!']
}
def random_response(self, animal):
return random.choice(self.responses[animal])
def talk(self, animal):
while True:
message = self.random_response(animal)
self.messages.put((animal, message))
time.sleep(random.randint(2, 5))
def chat_manager(self):
while True:
if not self.messages.empty():
animal, message = self.messages.get()
print(f"{animal} says: {message}")
time.sleep(1)
# Initialize animals and chat simulation
animal_names = ['Cat', 'Dog', 'Cow', 'Duck']
chat = AnimalChat(animal_names)
# Start animal conversations in separate threads
for animal in animal_names:
t = threading.Thread(target=chat.talk, args=(animal,))
t.start()
# Start chat manager in the main thread
chat_manager_thread = threading.Thread(target=chat.chat_manager)
chat_manager_thread.start()
import random
import time
import threading
import queue
class AnimalChat:
def __init__(self, animal_names):
self.animal_names = animal_names
self.messages = queue.Queue()
self.responses = {
'Cat': ['Meow!', 'Purr...', 'Hiss!'],
'Dog': ['Woof!', 'Bark!', 'Grr...'],
'Cow': ['Moo!', 'Moooo...', 'Mooo!'],
'Duck': ['Quack!', 'Quaaack!', 'Quack quack!']
}
def random_response(self, animal):
return random.choice(self.responses[animal])
def talk(self, animal):
while True:
message = self.random_response(animal)
self.messages.put((animal, message))
time.sleep(random.randint(2, 5))
def chat_manager(self):
while True:
if not self.messages.empty():
animal, message = self.messages.get()
print(f"{animal} says: {message}")
time.sleep(1)
# Initialize animals and chat simulation
animal_names = ['Cat', 'Dog', 'Cow', 'Duck']
chat = AnimalChat(animal_names)
# Start animal conversations in separate threads
for animal in animal_names:
t = threading.Thread(target=chat.talk, args=(animal,))
t.start()
# Start chat manager in the main thread
chat_manager_thread = threading.Thread(target=chat.chat_manager)
chat_manager_thread.start()
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report
# Load dataset
df = pd.read_csv('https://example.com/dataset.csv')
# Data preprocessing
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Parameter grid for GridSearch
param_grid = {
'n_estimators': [100, 200, 300],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': [10, 20, 30, None],
'criterion': ['gini', 'entropy']
}
# GridSearchCV for hyperparameter tuning
rf = RandomForestClassifier(random_state=42)
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
# Best parameters and model evaluation
print("Best Parameters:", grid_search.best_params_)
best_rf = grid_search.best_estimator_
y_pred = best_rf.predict(X_test)
print(classification_report(y_test, y_pred))
# Feature importance
importances = best_rf.feature_importances_
indices = np.argsort(importances)[::-1]
# Plot feature importances
plt.figure()
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices], align='center')
plt.xticks(range(X.shape[1]), X.columns[indices], rotation=90)
plt.tight_layout()
plt.show()
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import classification_report
# Load dataset
df = pd.read_csv('https://example.com/dataset.csv')
# Data preprocessing
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Parameter grid for GridSearch
param_grid = {
'n_estimators': [100, 200, 300],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': [10, 20, 30, None],
'criterion': ['gini', 'entropy']
}
# GridSearchCV for hyperparameter tuning
rf = RandomForestClassifier(random_state=42)
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
# Best parameters and model evaluation
print("Best Parameters:", grid_search.best_params_)
best_rf = grid_search.best_estimator_
y_pred = best_rf.predict(X_test)
print(classification_report(y_test, y_pred))
# Feature importance
importances = best_rf.feature_importances_
indices = np.argsort(importances)[::-1]
# Plot feature importances
plt.figure()
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices], align='center')
plt.xticks(range(X.shape[1]), X.columns[indices], rotation=90)
plt.tight_layout()
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import silhouette_score
class KMeans:
def __init__(self, n_clusters, max_iter=300):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = None
def initialize_centroids(self, X):
indices = np.random.choice(X.shape[0], self.n_clusters, replace=False)
self.centroids = X[indices]
def assign_clusters(self, X):
distances = np.array([np.linalg.norm(X - centroid, axis=1) for centroid in self.centroids])
return np.argmin(distances, axis=0)
def update_centroids(self, X, labels):
self.centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.n_clusters)])
def fit(self, X):
self.initialize_centroids(X)
for _ in range(self.max_iter):
labels = self.assign_clusters(X)
prev_centroids = self.centroids.copy()
self.update_centroids(X, labels)
if np.all(prev_centroids == self.centroids):
break
def predict(self, X):
return self.assign_clusters(X)
def inertia(self, X, labels):
total_inertia = 0
for i in range(self.n_clusters):
cluster_points = X[labels == i]
distances = np.linalg.norm(cluster_points - self.centroids[i], axis=1)
total_inertia += np.sum(distances ** 2)
return total_inertia
def silhouette_score(self, X, labels):
return silhouette_score(X, labels)
# Load and prepare the dataset
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and fit the KMeans model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X_train)
# Predict and evaluate the model
predictions = kmeans.predict(X_test)
accuracy = np.mean(predictions == y_test)
print("Accuracy:", accuracy)
# Calculate and display inertia
inertia = kmeans.inertia(X_test, predictions)
print("Inertia:", inertia)
# Calculate and display silhouette score
sil_score = kmeans.silhouette_score(X_test, predictions)
print("Silhouette Score:", sil_score)
# Visualize the clustering
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap='viridis')
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], s=300, c='red')
plt.title('KMeans Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import silhouette_score
class KMeans:
def __init__(self, n_clusters, max_iter=300):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = None
def initialize_centroids(self, X):
indices = np.random.choice(X.shape[0], self.n_clusters, replace=False)
self.centroids = X[indices]
def assign_clusters(self, X):
distances = np.array([np.linalg.norm(X - centroid, axis=1) for centroid in self.centroids])
return np.argmin(distances, axis=0)
def update_centroids(self, X, labels):
self.centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.n_clusters)])
def fit(self, X):
self.initialize_centroids(X)
for _ in range(self.max_iter):
labels = self.assign_clusters(X)
prev_centroids = self.centroids.copy()
self.update_centroids(X, labels)
if np.all(prev_centroids == self.centroids):
break
def predict(self, X):
return self.assign_clusters(X)
def inertia(self, X, labels):
total_inertia = 0
for i in range(self.n_clusters):
cluster_points = X[labels == i]
distances = np.linalg.norm(cluster_points - self.centroids[i], axis=1)
total_inertia += np.sum(distances ** 2)
return total_inertia
def silhouette_score(self, X, labels):
return silhouette_score(X, labels)
# Load and prepare the dataset
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and fit the KMeans model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X_train)
# Predict and evaluate the model
predictions = kmeans.predict(X_test)
accuracy = np.mean(predictions == y_test)
print("Accuracy:", accuracy)
# Calculate and display inertia
inertia = kmeans.inertia(X_test, predictions)
print("Inertia:", inertia)
# Calculate and display silhouette score
sil_score = kmeans.silhouette_score(X_test, predictions)
print("Silhouette Score:", sil_score)
# Visualize the clustering
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap='viridis')
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], s=300, c='red')
plt.title('KMeans Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import silhouette_score
class KMeans:
def __init__(self, n_clusters, max_iter=300):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = None
def initialize_centroids(self, X):
indices = np.random.choice(X.shape[0], self.n_clusters, replace=False)
self.centroids = X[indices]
def assign_clusters(self, X):
distances = np.array([np.linalg.norm(X - centroid, axis=1) for centroid in self.centroids])
return np.argmin(distances, axis=0)
def update_centroids(self, X, labels):
self.centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.n_clusters)])
def fit(self, X):
self.initialize_centroids(X)
for _ in range(self.max_iter):
labels = self.assign_clusters(X)
prev_centroids = self.centroids.copy()
self.update_centroids(X, labels)
if np.all(prev_centroids == self.centroids):
break
def predict(self, X):
return self.assign_clusters(X)
def inertia(self, X, labels):
total_inertia = 0
for i in range(self.n_clusters):
cluster_points = X[labels == i]
distances = np.linalg.norm(cluster_points - self.centroids[i], axis=1)
total_inertia += np.sum(distances ** 2)
return total_inertia
def silhouette_score(self, X, labels):
return silhouette_score(X, labels)
# Load and prepare the dataset
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and fit the KMeans model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X_train)
# Predict and evaluate the model
predictions = kmeans.predict(X_test)
accuracy = np.mean(predictions == y_test)
print("Accuracy:", accuracy)
# Calculate and display inertia
inertia = kmeans.inertia(X_test, predictions)
print("Inertia:", inertia)
# Calculate and display silhouette score
sil_score = kmeans.silhouette_score(X_test, predictions)
print("Silhouette Score:", sil_score)
# Visualize the clustering
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap='viridis')
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], s=300, c='red')
plt.title('KMeans Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import silhouette_score
class KMeans:
def __init__(self, n_clusters, max_iter=300):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.centroids = None
def initialize_centroids(self, X):
indices = np.random.choice(X.shape[0], self.n_clusters, replace=False)
self.centroids = X[indices]
def assign_clusters(self, X):
distances = np.array([np.linalg.norm(X - centroid, axis=1) for centroid in self.centroids])
return np.argmin(distances, axis=0)
def update_centroids(self, X, labels):
self.centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.n_clusters)])
def fit(self, X):
self.initialize_centroids(X)
for _ in range(self.max_iter):
labels = self.assign_clusters(X)
prev_centroids = self.centroids.copy()
self.update_centroids(X, labels)
if np.all(prev_centroids == self.centroids):
break
def predict(self, X):
return self.assign_clusters(X)
def inertia(self, X, labels):
total_inertia = 0
for i in range(self.n_clusters):
cluster_points = X[labels == i]
distances = np.linalg.norm(cluster_points - self.centroids[i], axis=1)
total_inertia += np.sum(distances ** 2)
return total_inertia
def silhouette_score(self, X, labels):
return silhouette_score(X, labels)
# Load and prepare the dataset
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and fit the KMeans model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X_train)
# Predict and evaluate the model
predictions = kmeans.predict(X_test)
accuracy = np.mean(predictions == y_test)
print("Accuracy:", accuracy)
# Calculate and display inertia
inertia = kmeans.inertia(X_test, predictions)
print("Inertia:", inertia)
# Calculate and display silhouette score
sil_score = kmeans.silhouette_score(X_test, predictions)
print("Silhouette Score:", sil_score)
# Visualize the clustering
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap='viridis')
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], s=300, c='red')
plt.title('KMeans Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
OUR SERVICE
OUR SERVICE
OUR
SERVICE
事業内容
-
WEBシステム開発/WEBサイト制作と、それに付帯するデジタル/ITに関わるあらゆるソリューションの提供を行っています。
- WEBシステム開発WEB DEVELOPMENT
- WEBサイト制作WEB DESIGN
- デジタルマーケティングDIGITAL MARKETING
- ITコンサルティングIT CONSULTING
-
- WEBシステム開発
- WEBサイト制作
- デジタルマーケティング
- ITコンサルティング



CASE STUDY
CASE STUDY
CASE
STUDY
開発事例
-
最新の技術と業界のベストプラクティスを活用して、あらゆるビジネスニーズに合わせた高性能かつ拡張性・柔軟性に優れたWEBシステム/サービス/アプリケーションを開発します。
- カスタマーサポートシステム
- スクール向け生徒管理システム
- モール型ECプラットフォーム
- SNSアプリケーション
- オンライン学習システム
-
カスタマーサポートシステム
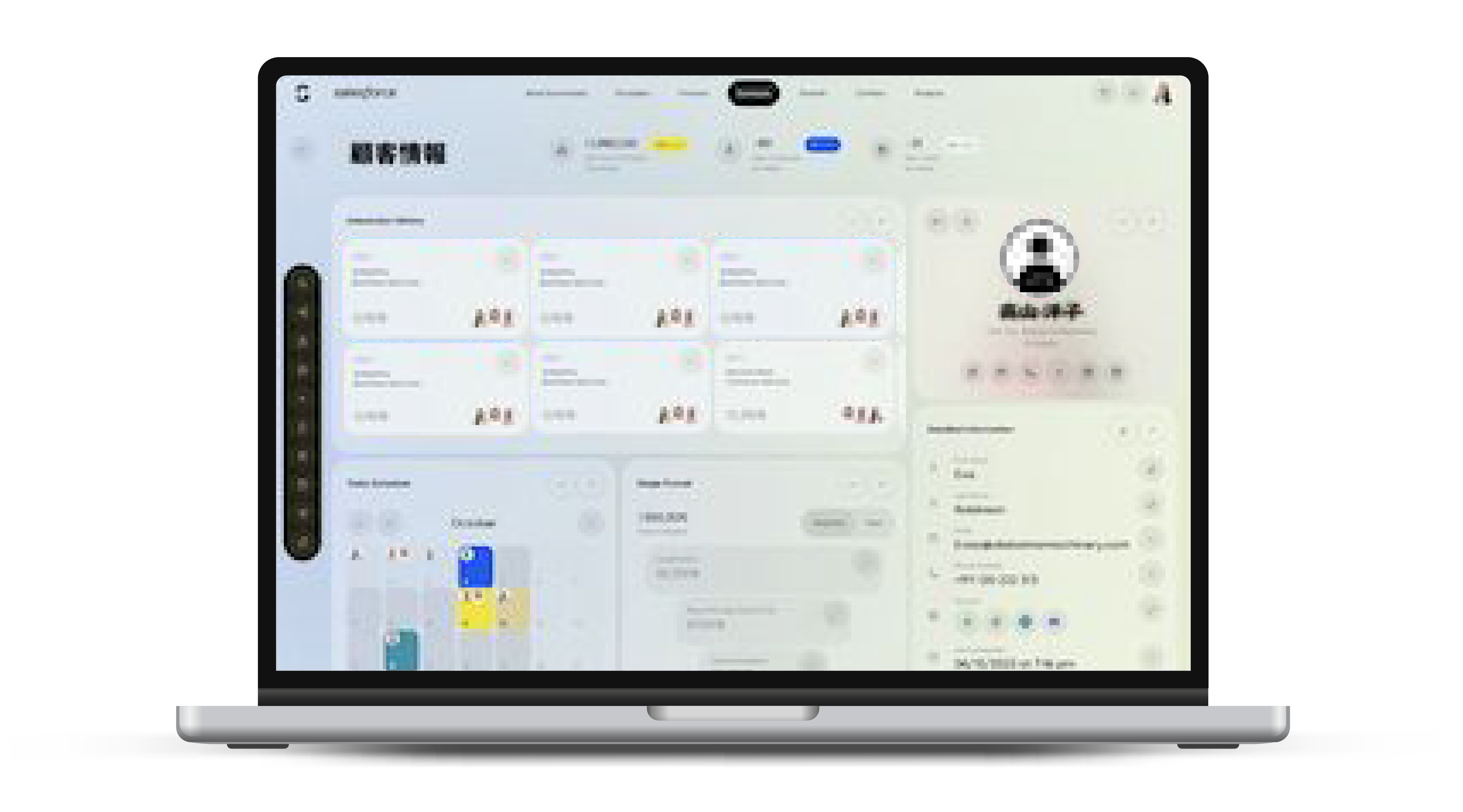 KEY FEATURE
KEY FEATURE- チャットボット
- ライブチャット
- ナレッジベースの管理
- 満足度の評価
企業が顧客に迅速かつ効果的なサポートを提供するためのオンラインカスタマーサポートシステムの開発です。このシステムは、チャットボットやライブチャット、FAQとナレッジベースの管理、顧客満足度の評価、フィードバック収集等を含む多様な機能を備えています。 -
スクール向け管理システム
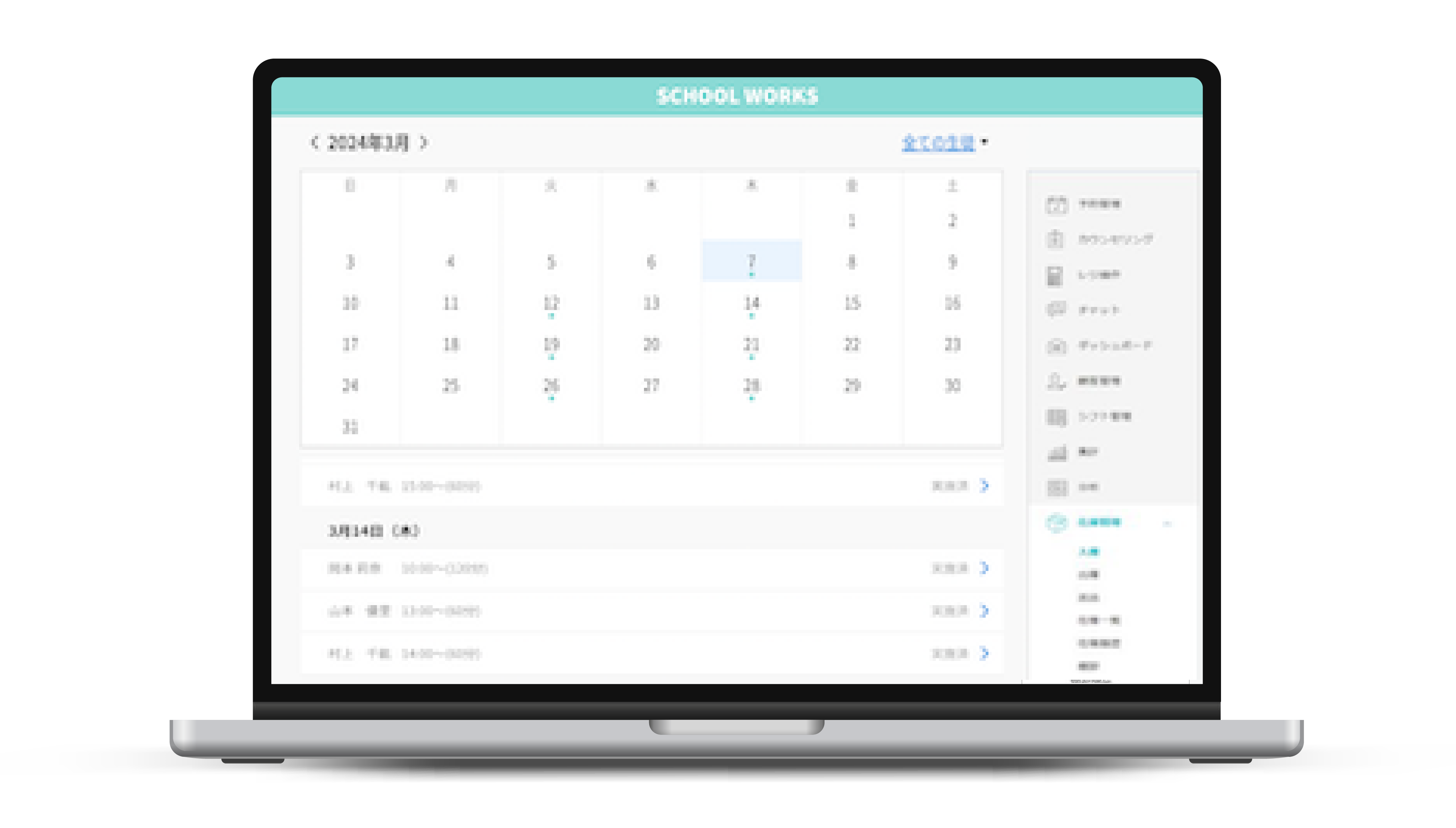 KEY FEATURE
KEY FEATURE- 成績の管理
- 出席管理と通知機能
- 保護者向けポータル
- 月謝の支払い管理
教育機関が日常業務を効率的に管理し、教師、学生、保護者の間のコミュニケーションを強化するために設計された包括的なソリューションです。このシステムは、学籍管理、出席管理、成績管理、授業計画、コミュニケーションツールなど、多岐にわたる機能を提供します。 -
モール型ECプラットフォーム
 KEY FEATURE
KEY FEATURE- 複数店舗の一元管理
- 多様な支払い方法
- 満足度の評価
複数の店舗やブランドが一つのオンラインモール内で商品を販売できるように設計された総合的なソリューションです。このプラットフォームは、各店舗が独自のショップを持ちながら、統一されたユーザーエクスペリエンスを提供し、顧客が一つの場所で様々な商品を購入できる利便性を実現します。 -
SNSアプリケーション
 KEY FEATURE
KEY FEATURE- フォロー/いいね
- スレッド/掲示板
- レコメンド
- イベント作成
特定のニーズに特化したユーザーが簡単にコミュニケーションを取り、コンテンツを共有できるソーシャルネットワーキングアプリです。このアプリは、ニュースフィード、メッセージング、グループ作成などの機能を提供します。 -
オンライン学習システム
 KEY FEATURE
KEY FEATURE- コースの作成と管理
- 課題管理
- 進捗追跡と評価
- ビデオストリーミング
教育機関や企業向けのオンライン学習プラットフォームの開発です。このプラットフォームは、ユーザーがオンラインで簡単に学習できる環境を提供します。学習の進捗や課題の提出等を包括的に管理することで、効果的に知識を身につけることができます。
TECHNOLOGY
TECHNOLOGY
TECHNOLOGY
STUCK
技術構成
CONPANY PROFILE
CONPANY PROFILE
COMPANY
PROFILE
会社情報
-
商号株式会社WORLDEST(ワールデスト)英名: WORLDEST Ltd.設立令和6年4月1日本社所在地広島県福山市柳津町5-1-5代表取締役福田 博之


CONTACT FORM
CONTACT FORM
CONTACT
FORM
お問い合わせ
下記の内容でよろしいですか?
お名前
様
メールアドレス
お問い合わせ内容
ありがとうございます!
内容を確認して返信致しますので、少しお待ちください。